
Zabezpieczanie systemów IT w chmurze obliczeniowej – przewodnik dla CTO
enova365
Spis treści
Michał Kaźmierczyk, CTO w Grupie Enteo, dzieli się dobrymi praktykami w zakresie wyboru odpowiedniego modelu korzystania z systemów IT, dostawcy usług i infrastruktury. Radzi także, jak skutecznie chronić stacje użytkowników oraz serwery aplikacyjne i dostęp do terminala.
Dlaczego rośnie rola bezpieczeństwa systemów IT?
Współczesne firmy coraz więcej procesów związanych bezpośrednio ze swoją działalnością realizują z wykorzystaniem narzędzi cyfrowych – w tym systemów informatycznych np. klasy ERP, CRM czy BI. Cyfryzacja jest podstawowym elementem zwiększania efektywności, a zasadnicza większość przedsiębiorców, zwłaszcza wprost proporcjonalnie do skali firmy, wskaże, że przy niedziałających systemach IT nie są w stanie skutecznie pracować.
Zwiększenie wykorzystania i uzależnienia firm od IT sprawia również, że gromadzą one coraz większe zasoby danych, często o niezwykłej wadze jakościowej, które nie powinny lub wręcz nie mogą być dostępne gronu szerszemu niż wybrani pracownicy firmy i jej Klienci.
Wszystko to, sprawia, że aspekty bezpieczeństwa wykorzystywanych systemów zaczynają odgrywać istotną rolę w procesie zarządzania.
Bezpieczeństwo w takim aspekcie należy rozumieć holistycznie jak zespół procesów i narzędzi gwarantujący, że firmowe systemy i przetwarzane w nich dane będą zarówno dostępne, jak i poufne i integralne (nie zmodyfikowane przez osoby nie uprawnione).

ABC chmury
Czy chmura jest dla mnie?
Rozważając nie tylko aspekty bezpieczeństwa, ale i efektywność kosztową (ile IT kosztuje moją firmę) oraz operacyjną (jak sprawnie mogę zmieniać i rozwijać swoje systemy), na pewnym etapie pojawia się pytanie o model przetwarzania.
Pytanie to, w pewien sposób fundamentalne, ma na celu wybór między umiejscowieniom swoich systemów w infrastrukturze własnej lub, co obecnie niezwykle popularne, w chmurze obliczeniowej.
Odpowiedź na pytanie, który model wybrać zależy od wielu elementów, kontekstu organizacji w tym skali, rodzaju prowadzonej działalności czy wymogów regulacyjnych. Nie ma możliwości, aby znaleźć całkowicie uniwersalną odpowiedź, ale można pokusić się o pewne uogólnienie bazujące na skali firmy i poziomie bezpieczeństwa.
Czy w chmurze jestem bezpieczniejszy?
Generalnie im mniejsza firma, tym mniejszym zespołem IT i budżetem dysponuje. Budowa infrastruktury IT zwłaszcza odpowiednio zabezpieczonej i umieszczonej w bezpiecznych, dobrze przygotowanych pomieszczeniach czy w centrum danych jest droga i skomplikowana. Odpowiednio wybrany, wiarygodny dostawca chmury obliczeniowej, spełniający normy i standardy bezpieczeństwa, gwarantuje najwyższy poziom zabezpieczeń fizycznych i technicznych, a jego infrastruktura winna być przygotowana i utrzymywana przez specjalistów. Na taki poziom i zakres infrastruktury pozwolić mogą sobie zwykle tylko największe firmy, stąd w kontekście bezpieczeństwa, rozumianego jako zabezpieczenie przez pożarem, kradzieżą, awarią prądu czy odpornością infrastruktury na awarie sprzętowe, dla firm mniejszych i średnich jest to zwykle najefektywniejsze rozwiązanie.
Dla firm większych dysponujących swoim zespołem IT i mogących sobie pozwolić na utrzymanie infrastruktury i jej poprawne wykonanie, tak aby gwarantowała należyte bezpieczeństwo, na pewnym poziomie chmura okazuje się zwykle rozwiązaniem o znacznie wyższym TCO (total cost of ownership). Takie firmy podejmując decyzje o chmurze biorą zwykle pod uwagę wykorzystanie usług, które trudno zbudować samodzielnie np. AI, zaawansowana analiza danych lub też uznają, że outsourcing infrastruktury pomimo większych kosztów niweluje istotne ryzyka np. wynikające z rotacji czy niedostępności wykwalifikowanej kadry lub szybkiej skalowalności infrastruktury.
Co oznacza, że system jest chmurze?
Zastanówmy się jednak, co to w ogóle oznacza, że system IT jest w chmurze? Na rynku panuje w tym aspekcie wiele nieporozumień, które często prowadzą do niewłaściwego rozumienia zarówno wad i zalet, jak i aspektów bezpieczeństwa, w tym podziału odpowiedzialności pomiędzy firmę a dostawcę.
W dużym uproszczeniu system jest w chmurze, jeśli infrastruktura tj. serwery, sieci, dyski, centra danych, oprogramowanie etc. nie jest w posiadaniu firmy (Klienta) a udostępnia je dostawca.
Dostawca dba, aby przygotować rozwiązania zgodnie z najlepszymi standardami i udostępnia je Klientom. Klient, odwrotnie niż w przypadku budowy własnej infrastruktury, ponosi tylko koszty operacyjne (OPEX), w skali dopasowanej do zakresu usług (infrastruktury chmurowej), jakich potrzebuje.
Wiemy już mniej więcej czym jest chmura, lecz co tak naprawdę kupujemy? W największym skrócie występują trzy modele znane pod angielskimi akronimami IaaS, PaaS, SaaS. Modele te określają zakres infrastruktury dostarczanej przez dostawcę, a tym samym, co najistotniejsze podział odpowiedzialności, czyli tym samym zakres ryzyk, które przejmuje dostawca a które pozostają po stronie klienta.
W modelu IaaS (Infrastruktura jako Usługa), dostawca dba o przygotowanie i utrzymanie centrum danych oraz dostarcza zasoby obliczeniowe w postaci serwerów fizycznych, dysków, sieci. Klient korzystając z takich zasobów samodzielnie (jego dział IT) tworzy systemy, a następnie je konfiguruje, instaluje aplikacje, zabezpiecza przed atakami i dba o ich stabilną pracę.
W modelu PaaS (Platforma jako usługa), dostawca dostarcza wszystko co w modelu IaaS oraz dodatkowo, przygotowuje dla Klienta gotowe systemy, o których działanie i zabezpieczenie dba. Klient instaluje na systemach aplikacje, zabezpiecza przed atakami i dba o ich odpowiednie działanie.
W modelu SaaS (Oprogramowanie jako Usługa), dostawca dostarcza wszystko co w modelu PaaS wraz gotowymi dostępnymi dla Klienta, utrzymywanymi oraz zabezpieczonymi przez dostawcę aplikacjami.
Podsumowując, w przypadku IaaS Klient potrzebuje specjalistów IT od systemów i aplikacji. W przypadku PaaS tylko specjalistów od aplikacji a wybierając SaaS skupia się na merytorycznym działaniu systemów pozostawiając całość IT w ramach dostawcy.
Idziemy do chmury …
Gdy już podjęliśmy decyzję o migracji do chmury, zdając sobie sprawę, że w aspekcie odporności na awarie chmura najczęściej gwarantuje wysoki lub bardzo wysoki poziom zabezpieczeń, kolejnym elementem do rozważenia jest bezpieczeństwo naszych danych (nawet w modelu SaaS) tj. odporność systemów na atak hakerski chroniąca nas zarówno przed wyciekiem czy kradzieżą, jak również niedostępnością.
Czy systemy w chmurze trzeba chronić inaczej?
Na początek należy wskazać, że niezależnie czy korzystamy z infrastruktury własnej czy w chmurze, z wyjątkiem modelu SaaS (o którym później) metody zabezpieczenia będą podobne, gdyż model przetwarzania nie wpływa istotnie na ochronę systemów przed atakami. Jedyną różnicą jest połączenie sieciowe. Przy własnej infrastrukturze, przynajmniej teoretycznie, może ona być dostępna tylko z biura/lokalizacji. W przypadku chmury dostęp jest zawsze przez Internet i należy podjąć działania zmierzające do jego zabezpieczenia np. tunele VPN.
Rodzaje systemów IT i sposoby dostępu do nich
Aby dobrze zrozumieć aspekty systemów IT związane z ich bezpieczeństwem, kluczowym jest ustalenie potencjalnych wektorów ataku, czyli mechanizmów jakie stosują hakerzy, aby zagrozić naszym danym i systemom. Wektory, zależne są od architektury systemu IT i metody jaką wykorzystują użytkownicy, aby z danego systemy skorzystać.
W dużym uproszczeniu współcześnie wyróżnić można dwa typy dostępu:
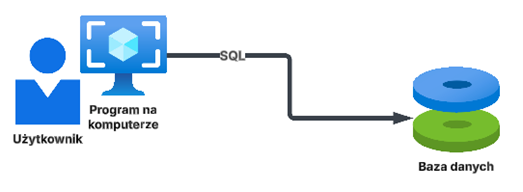
- Aplikacja desktop, w którym program (np. system ERP enova365) instalowany jest na stacji roboczej (komputerze) użytkownika i z tego komputera łączy się do serwera (bazy danych), na którym przechowywane są dane. W modelu tym całość obróbki danych odbywa się w programie na komputerze użytkownika.
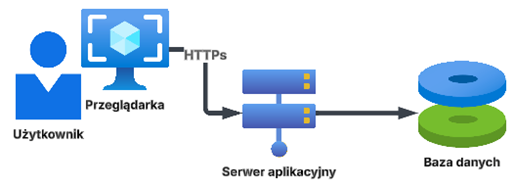
- Aplikacja webowa, w którym mamy układ m.in. dwóch serwerów. Na jednym znajduje się Klient, który z jednej strony publikuje interfejs aplikacji dostępny dla użytkownika przez przeglądarkę internetową, a z drugiej łączy się do bazy danych, w której przechowywane są dane. W modelu tym całość przetwarzania odbywa się na serwerze aplikacji, a na stacji użytkownika mamy tylko wyświetlone w przeglądarce internetowej wyniki przetwarzania.
Bezpieczeństwo w zależności od sposobu dostępu
Samą bazę danych relatywnie trudno jest chronić poza wykonywaniem regularnych aktualizacji i ścisłą izolacją sieciową samego serwera. W związku z tym generalna zasada jest następująca.
W przypadku aplikacji desktop chronimy użytkownika i jego stację, gdyż skuteczny atak hakerski na stację daje dostęp nie tylko do tego, co użytkownik wyświetla w programie, ale i do danych w bazie danych.
W przypadku chmury dla większości systemów opartych o aplikację desktop połączenie poprzez Internet jest zbyt wolne, aby system efektywnie łączył się do bazy danych. W takim wypadku stosuje się tzw. terminale tj. w chmurze umieszcza się dodatkowy serwer, który staje się stacją użytkownika.
Użytkownik łączy się do swojej chmurowej stacji (terminala) i tam uruchamia aplikację desktop (np. system ERP), która wtedy ma szybkie połączenie do bazy danych również znajdującej się w chmurze. Użytkownik po sieci Internet transmituje tylko obraz zmian, które wykonuje na terminalu.
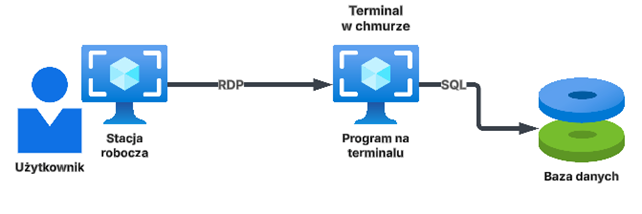
W tym aspekcie analogicznej ochronie, jak w klasycznym modelu stacja użytkownika, podlega właśnie nasz terminal.
W przypadku aplikacji webowej chronimy serwer aplikacyjny, gdyż dopiero skuteczny atak na ten serwer daje hakerowi dostęp do bazy danych.
Oczywiście żaden ze sposobów dostępu nie zwalnia nas z ochrony użytkownika i jego komputera, ale potencjalne spektrum ataku jest znacznie ograniczone, gdyż przejęcie stacji użytkownika nie powoduje automatycznie dostępu do danych w systemie.
Wybieramy model, dostawcę i architekturę
Wiemy już, jakie aspekty systemów należy chronić w zależności od rodzaju dostępu, jak również, które z elementów systemu chmurowego pozostają w zakresie dostawcy w zależności od modelu. Jasno widać, że znaczący wpływ na bezpieczeństwo firmowych danych ma dostawca oraz to, w jaki sposób przygotowana jest oferowana przez niego infrastruktura.
Niezwykle istotnym jest, aby wybrać takiego dostawcę, który z jednej strony gwarantuje, że wykorzystywane przez niego centrum danych oraz technologie i zastosowana architektura spełniają najwyższe możliwe standardy. Można w tym celu posłużyć, się np. certyfikacją w zakresie dostępności centrum danych czy normami bezpieczeństwa np. ISO 27001 czy 27017. Ważne jest, aby dostawca w wiarygodny sposób pokazał czy i jak dba o nasze bezpieczeństwo.
Równie istotna jest transparentność i jasny podział odpowiedzialności.
Jeśli wybieramy model IaaS, oczekujmy pełnej możliwości konfiguracji zasobów, które udostępnia dostawca. W modelu PaaS wymagajmy, aby dostawca wziął całą odpowiedzialność za dostarczane systemy, w przypadku SaaS, aby aplikacja, którą kupujemy była nie tylko efektywna, ale i należycie zabezpieczona (co dostawca powinien wiarygodnie pokazać).
Powszechne błędy…
Częstymi błędami są mieszanie modeli, brak podstawowych zabezpieczeń czy podstawowe błędy architektoniczne.
#Błąd 1
Przykładowo, dostawca oferuje model IaaS, ale nie udostępnia portalu, w którym klient może w dowolnym momencie zarządzać przydzielonymi mu zasobami np. tworzyć systemy czy sieci, zmieniać ich konfiguracje, restartować etc.
#Błąd 2
Innym przykładem może być udostępnianie przez dostawcę gotowego systemu (model PaaS) ale pozostawianie go w 100% do konfiguracji i utrzymania prze Klienta.
#Błąd 3
Nie bez znaczenia jest także właściwa architektura. Jeśli kupujemy model PaaS, gdzie to dostawca dostarcza nam systemy w efekcie otrzymujemy pojedynczy system wystawiony do Internetu (lub nawet za VPN), na którym mamy i bazę danych i program a często i aplikacje webową. Taka architektura nie trzyma żadnych standardów i stwarza ogromne ryzyka.
…i jak im zapobiec?
W modelu SaaS, gdzie to dostawca jest w 99% odpowiedzialny zarówno za dostępność, jak i ochronę przed atakami, zabezpieczenia są niezwykle istotne, zarówno te proceduralne jak certyfikaty i procesy, jak i techniczne, czyli proaktywne systemy chroniące przed atakami, odpowiednia separacja i ciągły nadzór.
W każdym z modeli niezwykle istotna jest także technologia. Jeśli dostawca wykorzystuje powszechne komercyjne i wspierane technologie, możemy być bardziej pewni ich właściwego przygotowania oraz dajemy sobie możliwość wyjścia i zmiany dostawcy. Umieszczając systemy w chmurze, z technologią występującą rzadko lub nigdzie indziej znacznie utrudniamy naszej firmie migrację, stawiając dostawcę w uprzywilejowanej pozycji.
Wybierając dostawcę, kluczowym jest więc dopytanie się o wszystkie szczegóły, pełne zrozumienie podziału odpowiedzialności, zastosowanej architektury, mechanizmów zabezpieczeń i porównywanie ofert na zasadzie „jabłko do jabłka” nie zaś np. „jabłko do marchewki”. Fakt, że oba służą do jedzenia nie czyni ich jeszcze tym samym.
Trochę technikaliów
Przeszliśmy przez proces wyboru odpowiedniego dostawcy, który wiarygodnie i transparentnie dostarcza niezbędne nam zasoby w najodpowiedniejszym dla naszej firmy i jej zasobów modelu. Wiemy również, że w zależności od typu dostępu musimy chronić albo stację użytkownika albo serwer aplikacyjny, a w każdym z przypadków samego użytkownika. W jaki sposób najlepiej to techniczne zrealizować? Nie wchodząc w meandry technologii poniżej przedstawiam podstawowe zasady.
Ochrona stacji użytkownika – 4 zasady:
- Stosujemy sprawdzone i dobrej jakości oprogramowanie chroniące przed atakami i wirusami. Oprogramowanie powinno być zawsze aktualne i gwarantować ochronę nie tylko przed prostymi sygnaturowymi wirusami, ale przed nowoczesnymi atakami bazującymi na podatnościach zero-day czy szyfrowaniu plików. W nomenklaturze przyjęło się nazywać takie oprogramowanie NG-Endpoint często z modułem EDR (Early Detection and Response).
- Wykorzystujemy aktualne wspierane przez producenta oprogramowanie, w tym systemy operacyjne, dla których producent regularnie publikuje aktualizacje zabezpieczeń.
- Aktualizacja – dbamy, aby systemy i aplikacje były regularnie aktualizowane.
- Stosujemy największą możliwą separację sieciową tj. dążymy do sytuacji, w której atak na jedną ze stacji nie będzie miał możliwości rozpropagowania się na inne.
Ochrona serwera aplikacyjnego i dostępu do terminala – 6 zasad
- Jeśli to możliwe dążymy do nie publikowania systemów w Internecie tj. zamknięcie ich np. za połączeniem VPN (Virtual Private Network) lub ZTNA (Zero Trust Network Acces), gdzie dostęp do systemu otrzyma tylko wiarygodny użytkownik z wiarygodnego urządzenia.
- Jeśli profil biznesu wymaga publikacji systemu w Internecie np. do wymiany danych z Klientami (B2B, B2C), zawsze umieszczamy go za systemem tupy WAF (Web Aplication Firewall) dla aplikacji web czy IPS (Intrusion Prevention System) dla terminali czy aplikacji nie opartych o przeglądarkę webową.
- Wykorzystujemy aktualne, wspierane przez producenta oprogramowanie, w tym systemy operacyjne dla których producent regularnie publikuje aktualizacje zabezpieczeń.
- Dbamy, aby systemy i aplikacje były regularnie aktualizowane.
- Stosujemy największą możliwą separację sieciową tj. dążymy do sytuacji, w której atak na jedną ze stacji nie będzie miał możliwości rozpropagowania się na inne.
- Jeśli używamy chmury w modelu PaaS/SaaS upewniamy się, że dostawca stosuje przynajmniej ww. zabezpieczenia.
Ochrona użytkownika – 3 zasady
Niezależnie od modelu i sposób dostępu zawsze powinniśmy chronić samego użytkownika. Jego nieświadomość czy błąd może spowodować np. wyciek hasła czy kompromitację jego stacji i tym samym dać atakującemu prosty dostęp do naszych systemów.
Zawsze powinniśmy stosować:
- Ochronę poczty elektronicznej przed spamem i wrogą zawartością m.in. plikami z wirusami czy groźnymi linkami. Nie wystarczą tu proste mechanizmy od dostawców poczty, zawsze trzeba stosować dedykowane systemy zawierające m.in. technologie sandboxingu.
- Dbamy o bezpieczne uwierzytelnienie tj. takie logowanie do naszych systemów, aby upewnić się, że loguje się rzeczywiście użytkownik a nie, że ktoś wykradł jego hasło. Najprostszym mechanizmem do zastosowania, niezależnie od modelu, jest MFA czy uwierzytelnienie oparte o minimum dwa składniki np. login i hasło plus kod z SMS lub potwierdzenie logowania w aplikacji na telefonie.
- Bardziej rozbudowaną wersją jest zastosowanie uwierzytelniania opartego o kontekst tj. upewniamy się, że loguje się właściwy użytkownik z właściwego, odpowiednio zabezpieczonego urządzenia. W tym celu stosuje się zewnętrzne systemy tożsamości.
Na koniec należy pamiętać, że niezależnie od modelu, rodzaju dostępu i systemu powinniśmy zawsze dbać o posiadanie aktywnej kopii naszych danych. Zawsze trzeba się upewnić, że dostawca gwarantuje kopie zapasowe w innej lokalizacji niż przetwarzane są nasze dane, a jeśli korzystamy z usług IaaS powinniśmy sami o to zadbać zewnętrznymi mechanizmami.
Komentarze (0)
Nie ma tutaj jeszcze żadnego komentarza, bądź pierwszy!
Napisz komentarz
Przeczytaj również:
enova365 w Prószyński i S-ka: wydawnictwo, e-commerce i logistyka w jednym systemie
enova365
